 Redis - 学习笔记-总览
Redis - 学习笔记-总览
# Redis.conf
# 熟悉基本配置
位置
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf
config get * # 获取全部的配置
我们一般情况下,会单独拷贝出来一份进行操作。来保证初始文件的安全。
正如在 安装redis 中的讲解中拷贝一份
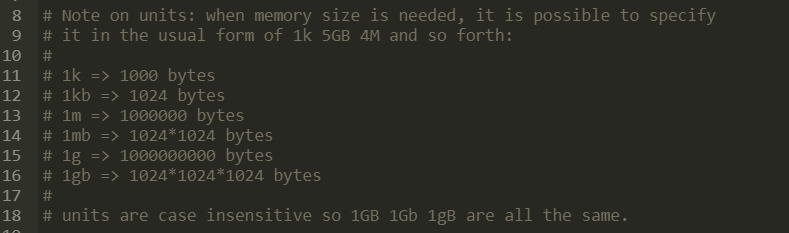
容量单位不区分大小写,G和GB有区别
include 组合多个配置

和Spring配置文件类似,可以通过includes包含,redis.conf 可以作为总文件,可以包含其他文件!
NETWORK 网络配置
bind 127.0.0.1 # 绑定的ip
protected-mode yes # 保护模式
port 6379 # 默认端口
2
3
GENERAL 通用
daemonize yes # 默认情况下,Redis不作为守护进程运行。需要开启的话,改为 yes
supervised no # 可通过upstart和systemd管理Redis守护进程
loglevel notice # 日志级别。可选项有:
# debug(记录大量日志信息,适用于开发、测试阶段)
# verbose(较多日志信息)
# notice(适量日志信息,使用于生产环境)
# warning(仅有部分重要、关键信息才会被记录)
logfile "" # 日志文件的位置,当指定为空字符串时,为标准输出
databases 16 # 设置数据库的数目。默认的数据库是DB 0
always-show-logo yes # 是否总是显示logo
2
3
4
5
6
7
8
9
10
11
12
SNAPSHOPTING 快照,持久化规则
由于Redis是基于内存的数据库,需要将数据由内存持久化到文件中
持久化方式:
- RDB
- AOF
# 900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化)
save 900 1
# 300秒(5分钟)内至少10个key值改变(则进行数据库保存--持久化)
save 300 10
# 60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化)
save 60 10000
2
3
4
5
6
RDB文件相关
stop-writes-on-bgsave-error yes # 持久化出现错误后,是否依然进行继续进行工作
rdbcompression yes # 使用压缩rdb文件 yes:压缩,但是需要一些cpu的消耗。no:不压缩,需要更多的磁盘空间
rdbchecksum yes # 是否校验rdb文件,更有利于文件的容错性,但是在保存rdb文件的时候,会有大概10%的性能损耗
dbfilename dump.rdb # dbfilenamerdb文件名称
dir ./ # dir 数据目录,数据库的写入会在这个目录。rdb、aof文件也会写在这个目录
2
3
4
5
6
7
8
9
REPLICATION主从复制
后面详细说
SECURITY安全
访问密码的查看,设置和取消
# 启动redis
# 连接客户端
# 获得和设置密码
config get requirepass
config set requirepass "123456"
#测试ping,发现需要验证
127.0.0.1:6379> ping
NOAUTH Authentication required.
# 验证
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> ping
PONG
2
3
4
5
6
7
8
9
10
11
12
13
14
15
客户端连接相关
maxclients 10000 最大客户端数量
maxmemory <bytes> 最大内存限制
maxmemory-policy noeviction # 内存达到限制值的处理策略
2
3
maxmemory-policy 六种方式
**1、volatile-lru:**利用LRU算法移除设置过过期时间的key。
2、allkeys-lru : 用lru算法删除lkey
**3、volatile-random:**随机删除即将过期key
**4、allkeys-random:**随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 不移除任何key,只是返回一个写错误。
redis 中的默认的过期策略是 volatile-lru 。
设置方式
config set maxmemory-policy volatile-lru
append only模式
(AOF相关部分)


appendfsync everysec # appendfsync aof持久化策略的配置
# no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
# always表示每次写入都执行fsync,以保证数据同步到磁盘。
# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
2
3
4
# Redis的持久化
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能!
Rdb 保存的是 dump.rdb 文件
# RDB(Redis DataBase)
什么是RDB
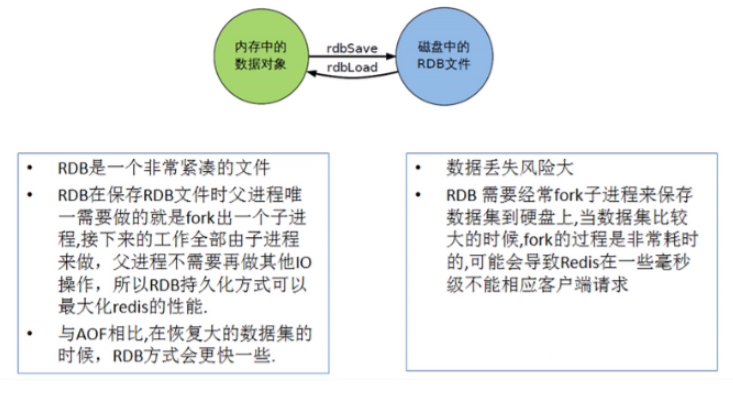
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快 照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。 这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量,环境变量,程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
配置位置及SNAPSHOTTING解析
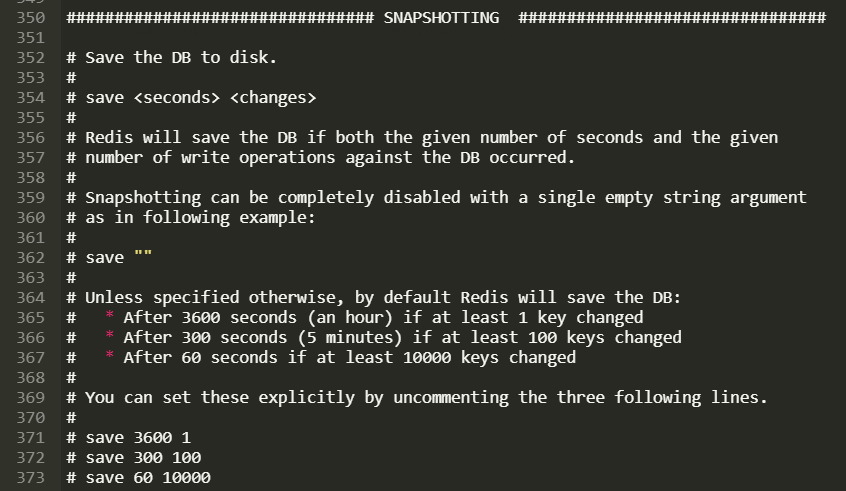
这里的触发条件机制,我们可以修改测试一下:
save 120 10 # 120秒内修改10次则触发RDB
RDB 是整合内存的压缩过的Snapshot,RDB 的数据结构,可以配置复合的快照触发条件。
如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以。
若要修改完毕需要立马生效,可以手动使用 save 命令!立马生效 !
save不是创建一个新进程去进行持久化
其余命令解析
Stop-writes-on-bgsave-error:如果配置为no,表示你不在乎数据不一致或者有其他的手段发现和控制,默认为yes。
rbdcompression:对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用 LZF算法进行压缩,如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。
rdbchecksum:在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约 10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。默认为yes。
如何触发RDB快照
1、配置文件中默认的快照配置,建议多用一台机子作为备份,复制一份 dump.rdb
2、命令save或者是bgsave
save 时只管保存,其他不管,全部阻塞
bgsave,Redis 会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave 命令获取最后一次成功执行快照的时间。
3、执行flushall命令,也会产生 dump.rdb 文件,但里面是空的,无意义 !
4、退出的时候也会产生 dump.rdb 文件!
如何恢复
1、将备份文件(dump.rdb)移动到redis安装目录并启动服务即可
2、CONFIG GET dir 获取目录
127.0.0.1:6379> config get dir
dir
/usr/local/bin
2
3
优点和缺点
优点:
1、适合大规模的数据恢复
2、对数据完整性和一致性要求不高
缺点:
1、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改
2、Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑。
小结
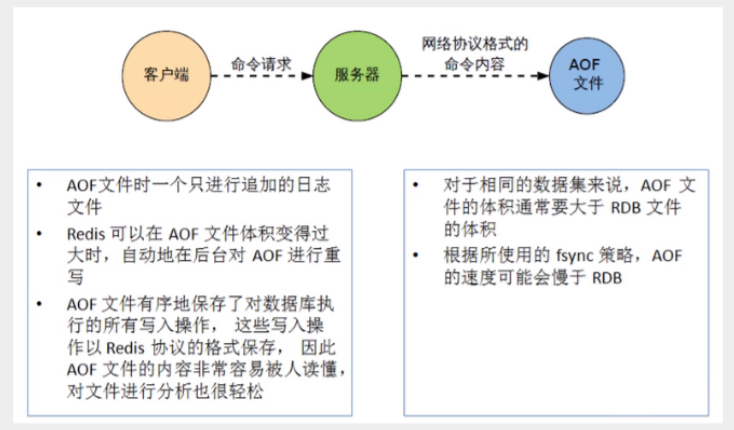
# AOF(Append Only File)
简介
以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件 的内容将写指令从前到后执行一次以完成数据的恢复工作
Aof保存的是 appendonly.aof 文件
配置
appendonly no
是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这 种方式在许多应用中已经足够用了
appendfilename "appendonly.aof"
appendfilename AOF 文件名称
appendfsync everysec
appendfsync aof持久化策略的配置
no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。 always表示每次写入都执行fsync,以保证数据同步到磁盘。 everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
No-appendfsync-on-rewrite
重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性
Auto-aof-rewrite-min-size
设置重写的基准值
Auto-aof-rewrite-percentage
设置重写的基准值
AOF 启动/修复/恢复
正常恢复:
启动:设置Yes,修改默认的appendonly no,改为yes 将有数据的aof文件复制一份保存到对应目录(config get dir) 恢复:重启redis然后重新加载
异常恢复:
启动:设置Yes
故意破坏 appendonly.aof 文件!
修复:命令redis-check-aof --fix appendonly.aof 进行修复
恢复:重启 redis 然后重新加载
Rewrite重写
AOF 采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis 就会启动AOF 文件的内容压缩,只保留可以恢复数据的最小指令集,可以 使用命令 bgrewriteaof !
重写原理:
AOF 文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再 rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧 的aof文件,这点和快照有点类似!
触发机制:
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的已被且文件大 于64M的触发。
优点和缺点
优点:
1、每修改同步:appendfsync always 同步持久化,每次发生数据变更会被立即记录到磁盘,性能较差但数据完整性比较好
2、每秒同步: appendfsync everysec 异步操作,每秒记录 ,如果一秒内宕机,有数据丢失
3、不同步: appendfsync no 从不同步
缺点:
1、相同数据集的数据而言,aof 文件要远大于 rdb文件,恢复速度慢于 rdb。
2、Aof 运行效率要慢于 rdb,每秒同步策略效率较好,不同步效率和rdb相同。
小结
# 总结
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF 文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有 AOF可能潜在的Bug,留着作为一个万一的手段。
5、性能建议
- 因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够 了,只保留 save 900 1 这条规则。
- 如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自 己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite 的最后将 rewrite 过程中产 生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite 的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重 写可以改到适当的数值。
- 如果不Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大笔IO,也 减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据, 启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。
# Redis 发布订阅
# 简介
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
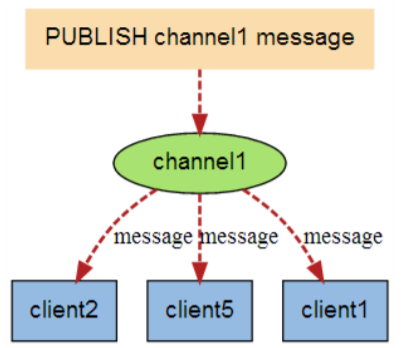
订阅/发布消息图:
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
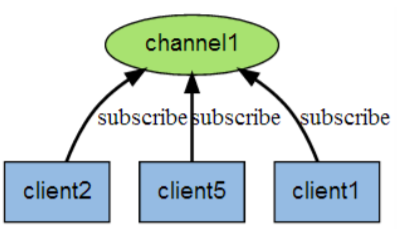
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
命令
下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [PSUBSCRIBE pattern [pattern ...]] 订阅一个或多个符合给定模式的频道。 |
| 2 | [PUBSUB subcommand [argument [argument ...]]] 查看订阅与发布系统状态。 |
| 3 | [PUBLISH channel message] 将信息发送到指定的频道。 |
| 4 | [PUNSUBSCRIBE [pattern [pattern ...]]] 退订所有给定模式的频道。 |
| 5 | [SUBSCRIBE channel [channel ...]] 订阅给定的一个或多个频道的信息。 |
| 6 | [UNSUBSCRIBE [channel [channel ...]]] 指退订给定的频道。 |
# 测试
以下实例演示了发布订阅是如何工作的。
我们先打开两个 redis-cli 客户端
在第一个 redis-cli 客户端,创建订阅频道名为 redisChat,输入SUBSCRIBE redisChat
redis 127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
2
3
4
5
在第二个客户端,发布两次消息,订阅者就能接收 到消息。
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Redis"
(integer) 1
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,java"
(integer) 1
2
3
4
订阅者的客户端会显示如下消息
- "message"
- "redisChat"
- "Hello,Redis"
- "message"
- "redisChat"
- "Hello,java"
# 原理
Redis是使用C实现的,通过分析 Redis 源码里的 pubsub.c 文件,了解发布和订阅机制的底层实现,来加深对 Redis 的理解。
Redis 通过 PUBLISH 、SUBSCRIBE 和 PSUBSCRIBE 等命令实现发布和订阅功能。
通过 SUBSCRIBE 命令订阅某频道后,redis-server 里维护了一个字典,字典的键就是一个个 channel ,而字典的值则是一个链表,链表中保存了所有订阅这个 channel 的客户端。SUBSCRIBE 命令的关键,就是将客户端添加到给定 channel 的订阅链表中。
通过 PUBLISH 命令向订阅者发送消息,redis-server 会使用给定的频道作为键,在它所维护的 channel 字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发布给所有订阅者。
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个 key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
使用场景:
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
# Redis主从复制
# 概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点 (master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。 Master以写为主,Slave 以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4、高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis高可用的基础。
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下:
1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较 大;
2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。
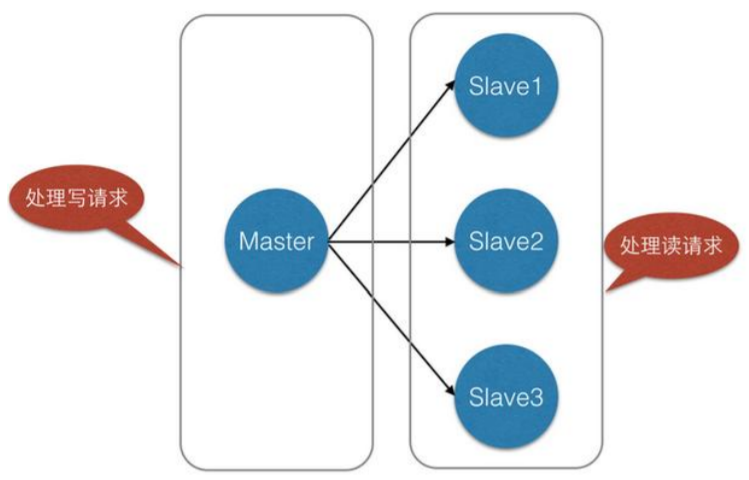
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。
对于这种场景,我们可以使如下这种架构:
# 环境配置
基本配置
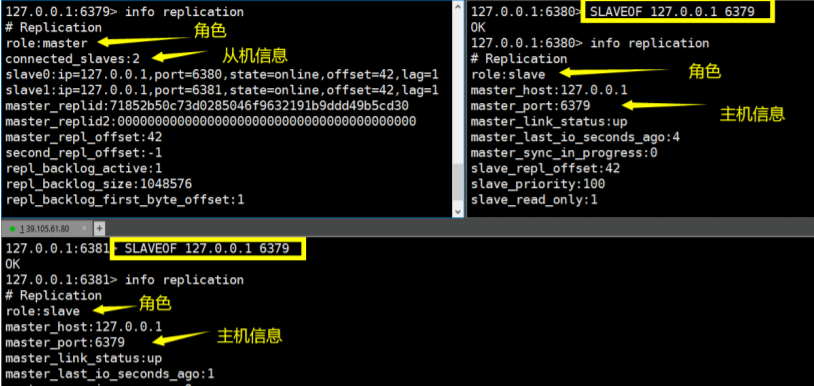
查看当前库的信息:info replication
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 从机数量
master_failover_state:no-failover
master_replid:1a6933acf7ec9711bfa0a1848976676557e1e6a0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
2
3
4
5
6
7
8
9
10
11
12
13
14
因为没有多个服务器,就以本地开启3个端口,模拟3个服务
既然需要启动多个服务,就需要多个配置文件。每个配置文件对应修改以下信息:
- 端口号(port)
- pid文件名(pidfile)
- 日志文件名(logfile)
- rdb文件名(dbfilename)
1、拷贝多个redis.conf 文件
端口分别是6379、6380、6381
[root@localhost ~]# cd /usr/local/bin/myconfig
[root@localhost myconfig]# ls
dump.rdb redis.conf
[root@localhost myconfig]# cp redis.conf redis79.conf
[root@localhost myconfig]# cp redis.conf redis80.conf
[root@localhost myconfig]# cp redis.conf redis81.conf
[root@localhost myconfig]# ls
dump.rdb redis79.conf redis80.conf redis81.conf redis.conf
2
3
4
5
6
7
8
分别修改配置上面四点对应的配置,举例:


配置好分别启动3个不同端口服务
redis-server myconfig/redis79.conf
redis-server myconfig/redis80.conf
redis-server myconfig/redis81.conf
redis-server myconfig/redis79.conf

# 一主二从
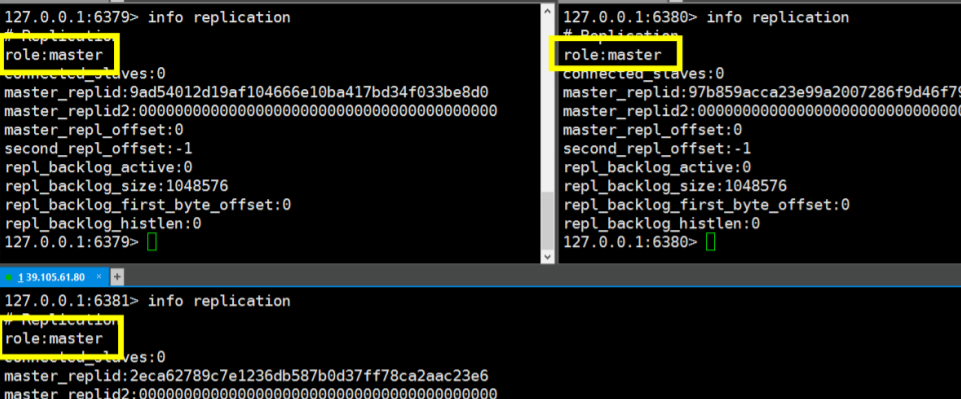
1、之后我们再分别开启redis连接,redis-cli -p 6379,redis-cli -p 6380,redis-cli -p 6381
通过指令
127.0.0.1:6379> info replication
可以发现,默认情况下,开启的每个redis服务器都是主节点
2、配置为一个Master 两个Slave(即一主二从)
6379为主,6380,6381为从
slaveof 127.0.0.1 6379
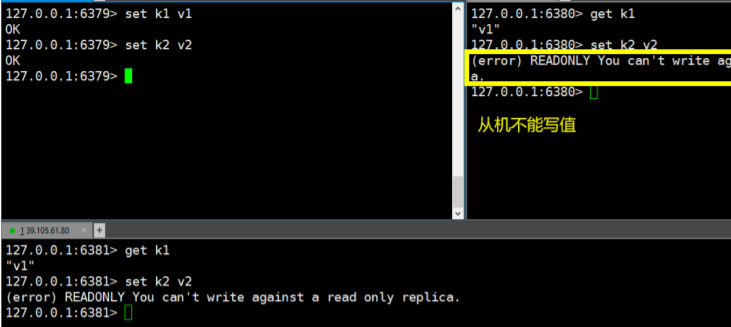
3、在主机设置值,在从机都可以取到!从机不能写值!
我们这里是使用命令搭建,是“暂时的”,也可去配置里进行修改,这样话则是“永久的”

使用规则
当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个同步原理。
有两种方式可以产生新的主机:看下文“谋权篡位”
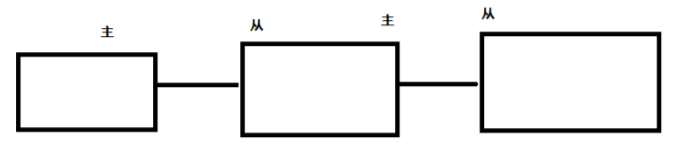
层层链路
上一个Slave 可以是下一个slave 和 Master,Slave 同样可以接收其他 slaves 的连接和同步请求,那么 该 slave 作为了链条中下一个的master,可以有效减轻 master 的写压力!
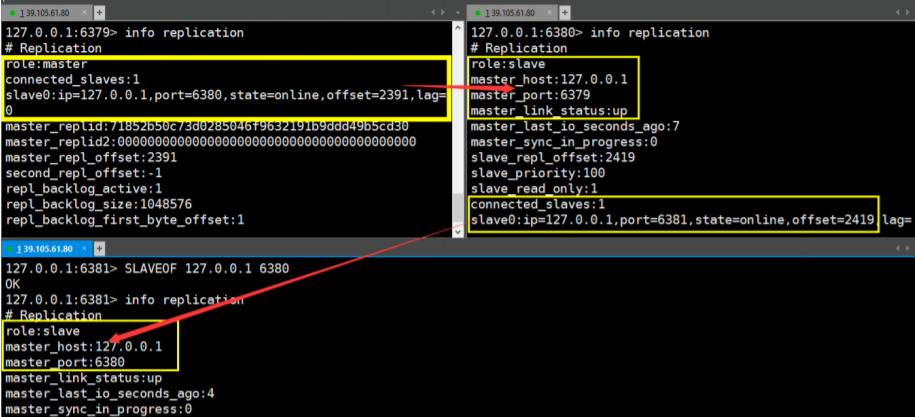
谋权篡位
有两种方式可以产生新的主机:
- 从机手动执行命令
slaveof no one,这样执行以后从机会独立出来成为一个主机 - 使用哨兵模式(自动选举)
复制原理
Slave 启动成功连接到 master 后会发送一个sync命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行 完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
# 哨兵模式
更多信息参考博客:https://www.jianshu.com/p/06ab9daf921d
概述
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工 干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑 哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵) 架构来解决这个问题。
谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独 立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
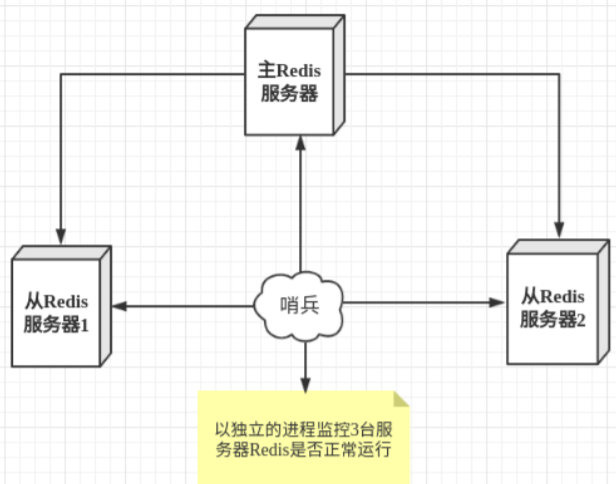
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。 各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
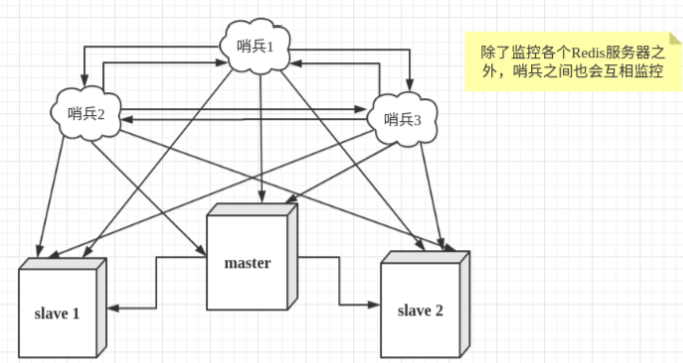
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认 为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一 定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。 切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为 客观下线。
配置测试
1、调整结构,6379带着80、81
2、自定义的 /myconfig 目录下新建 sentinel.conf 文件,名字千万不要错
3、配置哨兵,填写内容
sentinel monitor 被监控主机名字 127.0.0.1 6379 1例如:sentinel monitor mymaster 127.0.0.1 6379 1,
上面最后一个数字1,表示主机挂掉后slave投票看让谁接替成为主机,得票数多少后成为主机
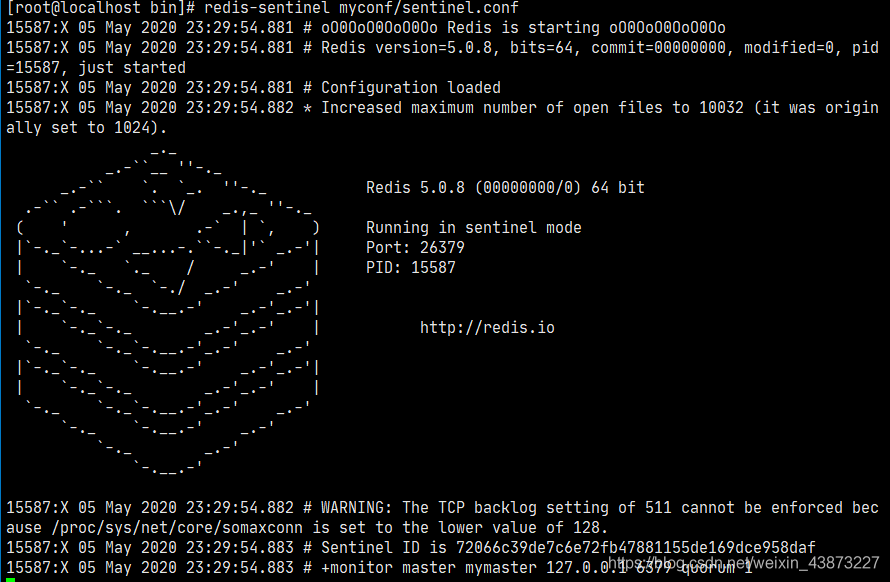
4、启动哨兵
Redis-sentinel myconfig/sentinel.conf
上述目录依照各自的实际情况配置,可能目录不同
成功启动哨兵模式
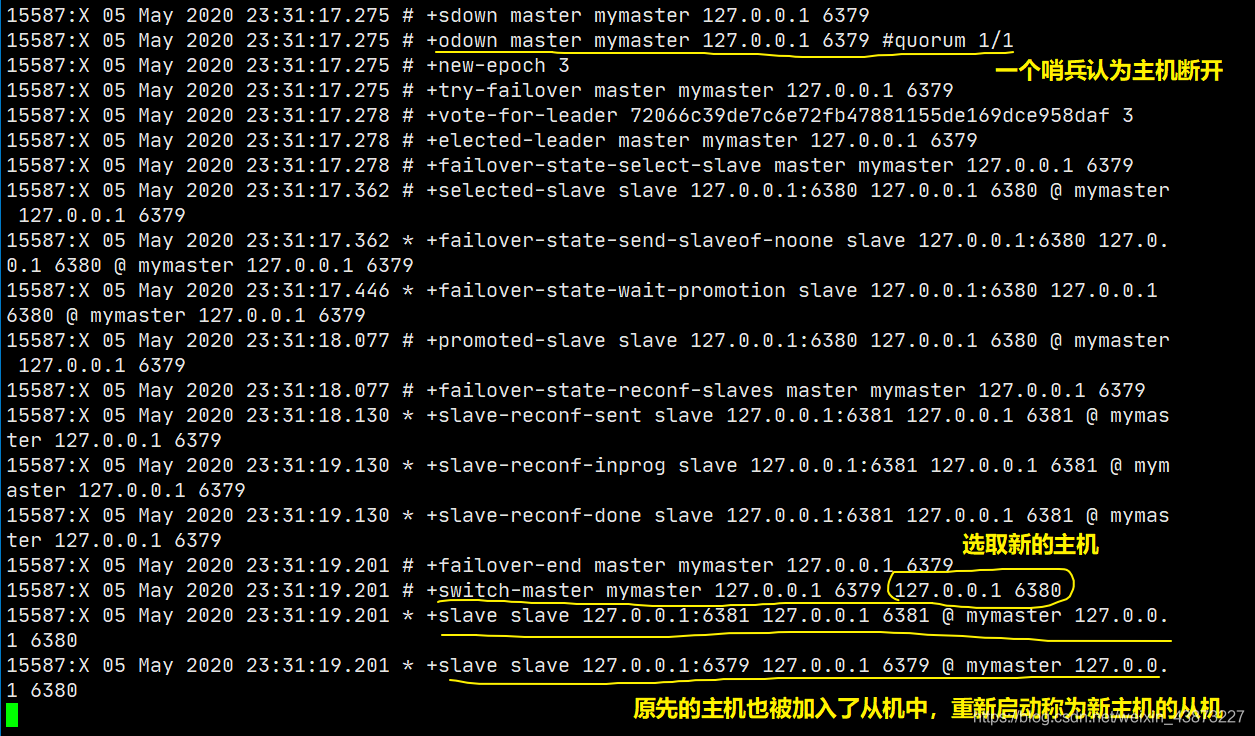
此时哨兵监视着我们的主机6379,当我们断开主机后:
哨兵模式的优缺点
优点
- 哨兵集群,基于主从复制模式,所有主从复制的优点,它都有
- 主从可以切换,故障可以转移,系统的可用性更好
- 哨兵模式是主从模式的升级,手动到自动,更加健壮
缺点:
- Redis不好在线扩容,集群容量一旦达到上限,在线扩容就十分麻烦
- 实现哨兵模式的配置其实是很麻烦的,里面有很多配置项
哨兵模式的全部配置
完整的哨兵模式配置文件 sentinel.conf
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
#这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
#一个是事件的类型,
#一个是事件的描述。
#如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 缓存穿透与雪崩
# 缓存穿透(查不到)
概念
在默认情况下,用户请求数据时,会先在缓存(Redis)中查找,若没找到即缓存未命中,再在数据库中进行查找,数量少可能问题不大,可是一旦大量的请求数据(例如秒杀场景)缓存都没有命中的话,就会全部转移到数据库上,造成数据库极大的压力,就有可能导致数据库崩溃。网络安全中也有人恶意使用这种手段进行攻击被称为洪水攻击。
解决方案
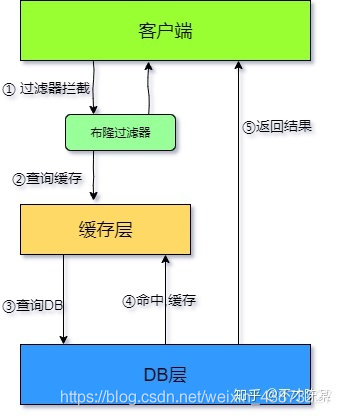
布隆过滤器
对所有可能查询的参数以Hash的形式存储,以便快速确定是否存在这个值,在控制层先进行拦截校验,校验不通过直接打回,减轻了存储系统的压力。
缓存空对象
一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
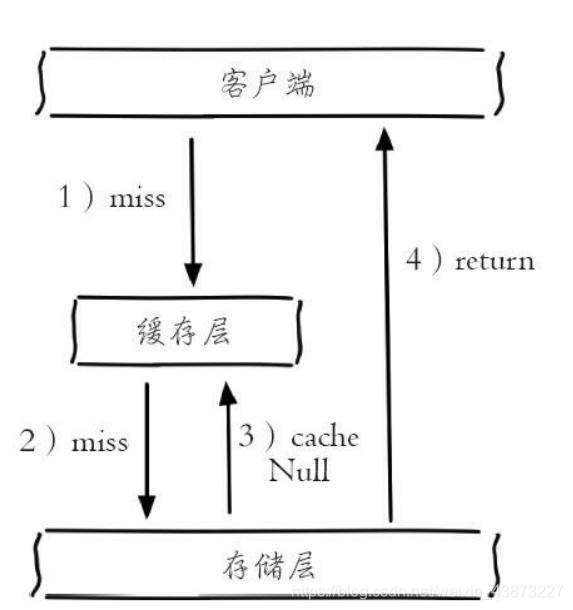
这样做有一个缺陷:存储空对象也需要空间,大量的空对象会耗费一定的空间,存储效率并不高。解决这个缺陷的方式就是设置较短过期时间
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
# 缓存击穿(量太大,缓存过期)
概念
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
解决方案
设置热点数据永不过期
这样就不会出现热点数据过期的情况,但是当Redis内存空间满的时候也会清理部分数据,而且此种方案会占用空间,一旦热点数据多了起来,就会占用部分空间。
加互斥锁(分布式锁)
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。保证同时刻只有一个线程访问。这样对锁的要求就十分高。
# 缓存雪崩
概念
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
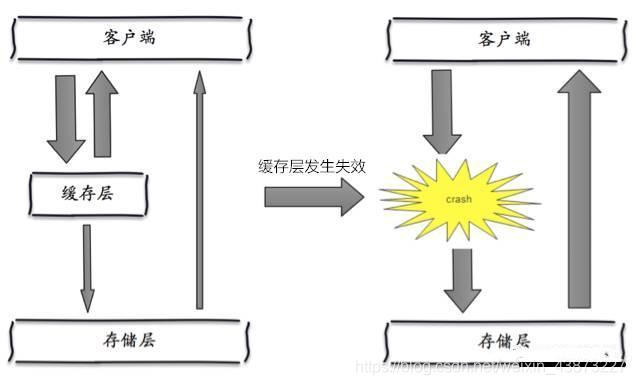
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然 形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就 是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知 的,很有可能瞬间就把数据库压垮。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。