 Redis - 概念和基础
Redis - 概念和基础
狂神redis视频教程视频教程:https://www.bilibili.com/video/BV1S54y1R7SB
# 概述
Redis:REmote DIctionary Server(远程字典服务器)
是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(Key/Value)分布式内存数据 库,基于内存运行,并支持持久化的NoSQL数据库,是当前最热门的NoSQL数据库之一,也被人们称为数据结构服务器
Redis与其他key-value缓存产品有以下三个特点
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的 key-value 类型的数据,同时还提供list、set、zset、hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
# 常用网站
官网
https://redis.io/
中文网
http://www.redis.cn
# 安装Redis
由于企业里面做Redis开发,99%都是Linux版的运用和安装,几乎不会涉及到Windows版,所以这里就以linux版为主,可以自己去测试玩玩,Windows安装及使用教程:https://www.cnblogs.com/xing-nb/p/12146449.html
linux直接去官网下载:https://redis.io/download
安装步骤(基于当时最新版6.2.1):
下载压缩包,放置Linux的目录下 /opt
在/opt 目录下解压,命令 :
tar -zxvf redis-6.2.1.tar.gz解压完成后出现文件夹:redis-6.2.1
进入目录:
cd redis-6.2.1在 redis-6.2.1 目录下执行
make命令运行make命令时故意出现的错误解析:
安装gcc (gcc是linux下的一个编译程序,是c程序的编译工具)
能上网: yum install gcc-c++
版本测试: gcc-v
二次make
Jemalloc/jemalloc.h:没有那个文件或目录
运行 make distclean 之后再make
Redis Test(可以不用执行)
如果make完成后执行
make install查看默认安装目录:
cd /usr/local/bin/usr 这是一个非常重要的目录,类似于windows下的Program Files,存放用户的程序

redis默认不是后台启动,修改文件
一般我们在 /usr/local/bin 目录下,创建myconfig目录,存放我们的配置文件
cd /usr/local/bin mkdir myconfig #创建目录 #拷贝配置文件 cd /opt/redis-6.2.1 cp redis.conf /usr/local/bin # 拷一个备份,养成良好的习惯,我们就修改这个文件 # 修改配置保证可以后台应用 vim redis.conf /daemonize #查找 :wq #保存1
2
3
4
5
6
7
8
9
10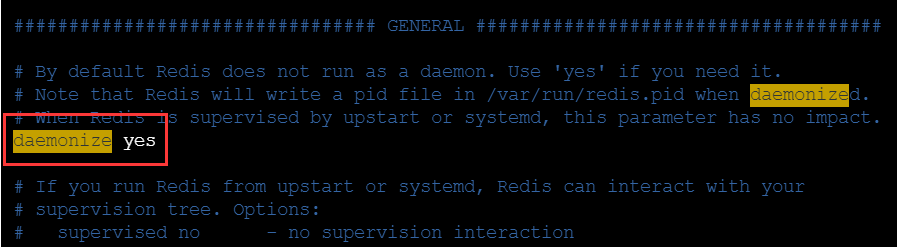
- A、redis.conf配置文件中daemonize守护线程,默认是NO。
- B、daemonize是用来指定redis是否要用守护线程的方式启动。
daemonize 设置yes或者no区别
daemonize:yes
redis采用的是单进程多线程的模式。当redis.conf中选项daemonize设置成yes时,代表开启守护进程模式。在该模式下,redis会在后台运行,并将进程pid号写入至redis.conf选项 pidfile设置的文件中,此时redis将一直运行,除非手动kill该进程。
daemonize:no
当daemonize选项设置成no时,当前界面将进入redis的命令行界面,exit强制退出或者关闭连接工具(putty,xshell等)都会导致redis进程退出。
启动测试一下!
启动redis服务
cd /usr/local/bin redis-server myconfig/redis.conf1
2redis客户端连接
redis-cli -p 63791观察地址的变化,如果连接成功,是直接连上的,redis默认端口号 6379

执行ping、get和set操作、退出
127.0.0.1:6379> ping PONG 127.0.0.1:6379> get hello (nil) 127.0.0.1:6379> set hello zhiyuan OK 127.0.0.1:6379> get hello "zhiyuan"1
2
3
4
5
6
7
8
关闭连接
127.0.0.1:6379> shutdown not connected> exit1
2
可以使用指令ps -ef|grep redis显示系统当前redis 进程信息,查看开启和关闭连接的变化
# 基础知识说明
# redis压力测试
Redis-benchmark是官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能。
redis 性能测试工具可选参数如下所示:
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 numreq 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
# 测试:100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能
cd /usr/local/bin
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
2
3
参考资料:https://www.runoob.com/redis/redis-benchmarks.html
# 基本数据库常识
默认16个数据库,类似数组下标从零开始,初始默认使用零号库
查看 redis.conf ,里面有默认的配置
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
2
3
4
Select命令切换数据库
127.0.0.1:6379> select 7
OK
127.0.0.1:6379[7]>
# 不同的库可以存不同的数据
2
3
4
Dbsize查看当前数据库的key的数量
127.0.0.1:6379> select 7
OK
127.0.0.1:6379[7]> DBSIZE
(integer) 0
127.0.0.1:6379[7]> select 0
OK
127.0.0.1:6379> DBSIZE
(integer) 5
127.0.0.1:6379> keys * # 查看具体的key
1) "counter:__rand_int__"
2) "mylist"
3) "k1"
4) "myset:__rand_int__"
5) "key:__rand_int__"
2
3
4
5
6
7
8
9
10
11
12
13
14
Flushdb:清空当前库
Flushall:清空全部的库
127.0.0.1:6379> DBSIZE
(integer) 5
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> DBSIZE
(integer) 0
2
3
4
5
6
# 关于redis的单线程
注:6.x版本有多线程,一般用不到,单线程足够应对
我们首先要明白,Redis很快!官方表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就 顺理成章地采用单线程的方案了!
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
Redis为什么这么快?
redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为 多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切 换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存 的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处 理这个事。在内存的情况下,这个方案就是最佳方案。
因为一次CPU上下文的切换大概在 1500ns 左右。从内存中读取 1MB 的连续数据,耗时大约为 250us, 假设1MB的数据由多个线程读取了1000次,那么就有1000次时间上下文的切换,那么就有1500ns * 1000 = 1500us ,我单线程的读完1MB数据才250us ,你光时间上下文的切换就用了1500us了,我还不算你每次读一点数据的时间。