 LinkedList
LinkedList
# LinkedList
# 引入
问题:在集合的任何位置(头部,中间,尾部)添加,获取,删除狗狗对象!
插入,删除操作频繁时,可使用LinkedList来提高效率
LinkedList提供对头部和尾部元素进行添加和删除操作的方法!
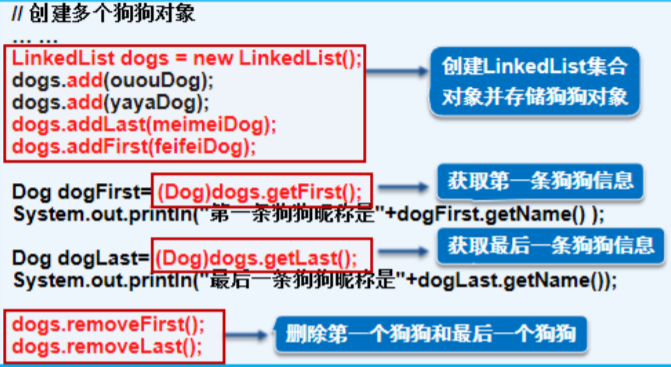
LinkedList的特殊方法
集合框架有何好处? Java集合框架中包含哪些接口和类? ArrayList和LinkedList有何异同?
# LinkedList概述
我们都知道它的底层是由链表实现的,所以我们要明白什么是链表?
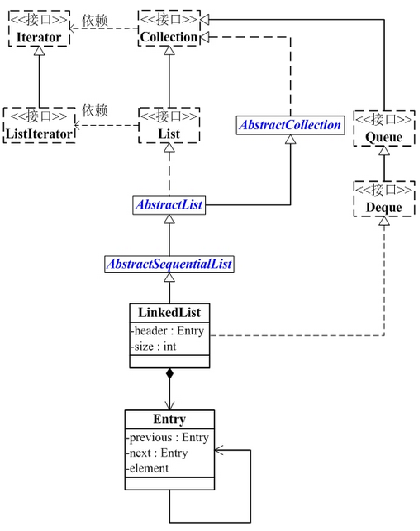
LinkedList是一种可以在任何位置进行高效地插入和移除操作的有序序列,它是基于双向链表实现的。
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
推荐文章:LinkList详解 (opens new window)
# 链表的数据结构
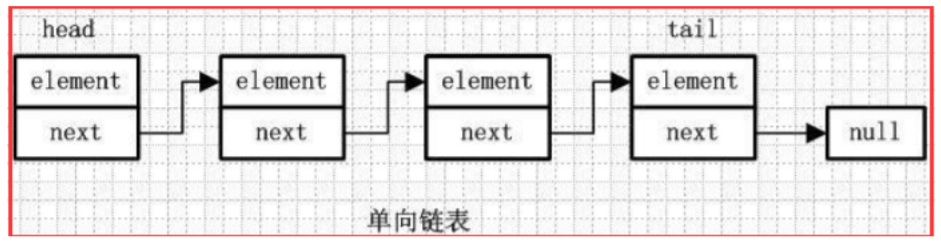
单向链表:
element:用来存放元素
next:用来指向下一个节点元素
通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
单向循环链表:
element、next 跟前面一样,在单向链表的最后一个节点的next会指向头节点,而不是指向null,这样存成一个环
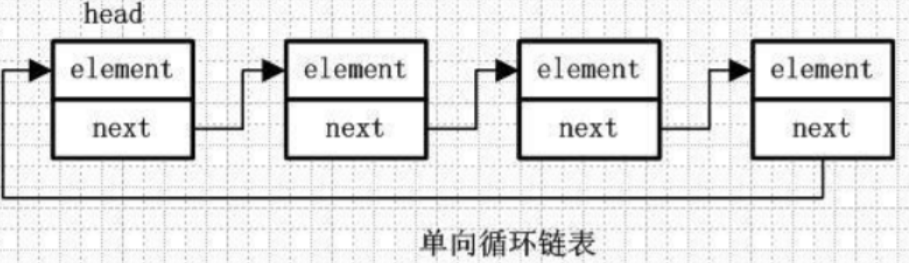
双向链表:
element:存放元素
pre:用来指向前一个元素
next:指向后一个元素
双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
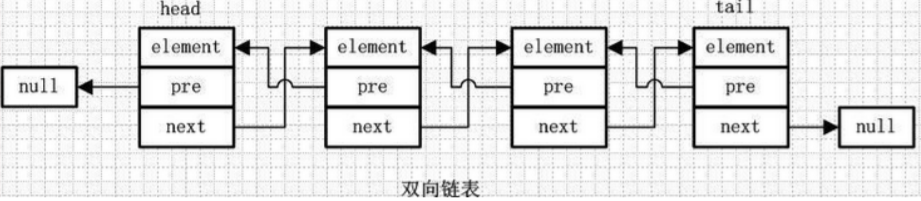
双向循环链表:
element、pre、next 跟前面的一样
第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。
【LinkedList的数据结构】

如上图所示,LinkedList底层使用的双向链表结构,有一个头结点和一个尾结点,双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
# LinkedList源码分析
接下来又到了大家喜欢的读源码环节**😄**
# 1、LinkedList的特性
在我们平常中,我们只知道一些常识性的特点:
1)是通过链表实现的 2)如果在频繁的插入,或者删除数据时,就用linkedList性能会更好。
那我们通过API去查看它的一些特性
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
这告诉我们,linkedList是一个双向链表,并且实现了List和Deque接口中所有的列表操作,并且能存储任何元素,包括null,这里我们可以知道linkedList除了可以当链表使用,还可以当作队列使用,并能进行相应的操作。
All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
这个告诉我们,linkedList在执行任何操作的时候,都必须先遍历此列表来靠近通过index查找我们所需要的的值。通俗点讲,这就告诉了我们这个是顺序存取,每次操作必须先按开始到结束的顺序遍历,随机存取,就是arrayList,能够通过index。随便访问其中的任意位置的数据,这就是随机列表的意思。
3)api中接下来讲的一大堆,就是说明linkedList是一个非线程安全的(异步),其中在操作Interator时, 如果改变列表结构(adddelete等),会发生fail-fast。
通过API再次总结一下LinkedList的特性:
异步,也就是非线程安全
双向链表。由于实现了list和Deque接口,能够当作队列来使用。
链表:查询效率不高,但是插入和删除这种操作性能好。
是顺序存取结构(注意和随机存取结构两个概念搞清楚)
# 2、继承结构以及层次关系
ctrl+h
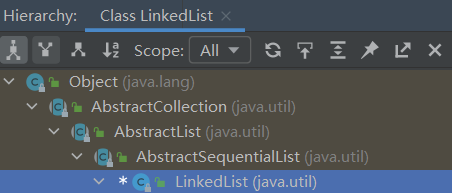
我们可以看到,linkedList在最底层,说明他的功能最为强大,并且细心的还会发现,arrayList有四层,这里多了一层AbstractSequentialList的抽象类,为什么呢?
通过API我们会发现:
1)减少实现顺序存取(例如LinkedList)这种类的工作,通俗的讲就是方便,抽象出类似LinkedList这种类的一些共同的方法
2)既然有了上面这句话,那么以后如果自己想实现顺序存取这种特性的类(就是链表形式),那么就继承这个AbstractSequentialList抽象类,如果想像数组那样的随机存取的类,那么就去实现AbstracList抽象类。
3)这样的分层,就很符合我们抽象的概念,越在高处的类,就越抽象,往在底层的类,就越有自己独特的个性。自己要慢慢领会这种思想。
4)LinkedList的类继承结构很有意思,我们着重要看是Deque接口,Deque接口表示是一个双端队列,那么也意味着LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。
public abstract class AbstractSequentialList<E>
extends AbstractList<E>
2
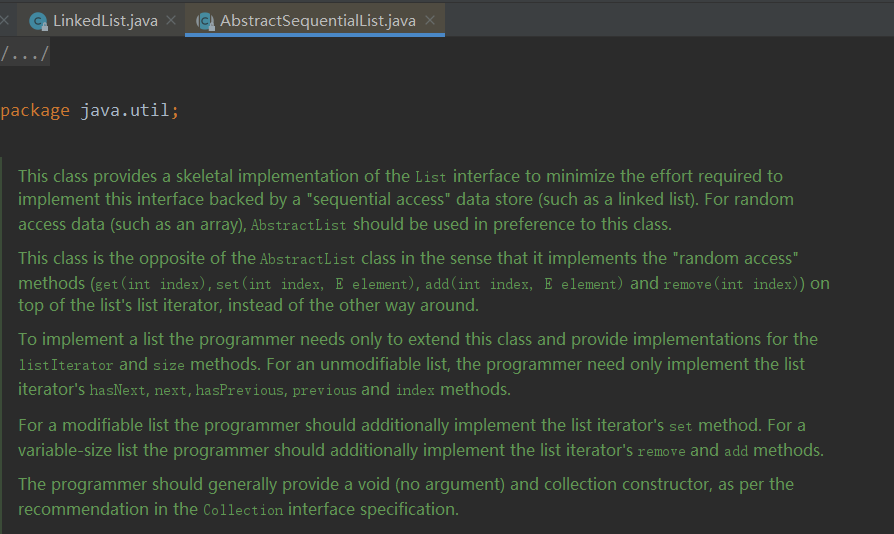
第一段:
这里第一段就解释了这个类的作用,这个类为实现list接口提供了一些重要的方法, 尽最大努力去减少实现这个“顺序存取”的特性的数据存储(例如链表)的什么 随机存取数据(例如数组)的类应该优先使用AbstractList 从上面就可以大概知道,AbstractSwquentialList这个类是为了减少LinkedList这种顺序存取的类的代码复杂度而抽象的一个类,
第二段:
这一段大概讲的就是这个AbstractSequentialList这个类和AbstractList这个类是完全相反 的。比如get、add这个方法的实现
第三段:
这里就是讲一些我们自己要继承该类,该做些什么事情,一些规范。
【接口实现分析】
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
}
2
3
4
5
6
List接口:列表,add、set、等一些对列表进行操作的方法
Deque接口:有队列的各种特性,
Cloneable接口:能够复制,使用那个copy方法。
Serializable接口:能够序列化。
应该注意到没有RandomAccess:那么就推荐使用iterator,在其中就有一个foreach,增强的for循环,其中原理也就是iterator,我们在使用的时候,使用foreach或者iterator都可以。
iterator:
public static void method() { List<String> l = new ArrayList<>(); l.add("hello"); l.add(0, "123"); l.add("789"); l.set(0, "456"); l.remove(0); ListIterator<String> lit = l.listIterator(); while (lit.hasNext()) { String next = lit.next(); // l.add("111"); lit.add("111"); System.out.println(next); } System.out.println(l); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3、类的属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 实际元素个数
transient int size = 0;
// 头结点
transient Node<E> first;
// 尾结点
transient Node<E> last;
}
2
3
4
5
6
7
8
9
10
11
LinkedList的属性非常简单,一个头结点、一个尾结点、一个表示链表中实际元素个数的变量。注意, 头结点、尾结点都有transient关键字修饰,这也意味着在序列化时该域是不会序列化的。
# 4、构造方法
两个构造方法(两个构造方法都是规范规定需要写的)
【空参构造函数】
public LinkedList() {
}
2
3
【有参构造函数】
//将集合c中的各个元素构建成LinkedList链表。
public LinkedList(Collection<? extends E> c) {
// 调用无参构造函数
this();
// 添加集合中所有的元素
addAll(c);
}
2
3
4
5
6
7
说明:会调用无参构造函数,并且会把集合中所有的元素添加到LinkedList中。
# 5、内部类(Node)
//根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里。
private static class Node<E> {
E item; // 数据域(当前节点的值)
Node<E> next; // 后继(指向当前一个节点的后一个节点)
Node<E> prev; // 前驱(指向当前节点的前一个节点)
// 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
说明:内部类Node就是实际的结点,用于存放实际元素的地方。
# 6、核心方法
# add()方法
public boolean add(E e) {
// 添加到末尾
linkLast(e);
return true;
}
2
3
4
5
说明:add函数用于向LinkedList中添加一个元素,并且添加到链表尾部。具体添加到尾部的逻辑是由 linkLast函数完成的。
【LinkLast(XXXXX)】
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last; //临时节点l(L的小写)保存last,也就是l指向了最后一个节点
final Node<E> newNode = new Node<>(l, e, null);////将e封装为节点,并且e.prev指向了最后一个节点
last = newNode;//newNode成为了最后一个节点,所以last指向了它
if (l == null)//判断是不是一开始链表中就什么都没有,如果没有,则newNode就成为了第一个节点,first和last都要指向它
first = newNode;
else //正常的在最后一个节点后追加,那么原先的最后一个节点的next就要指向现在真正的最后一个节点,原先的最后一个节点就变成了倒数第二个节点
l.next = newNode;
size++; ;//添加一个节点,size自增
modCount++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
说明:对于添加一个元素至链表中会调用add方法 -> linkLast方法。
【举例一】
List<Integer> lists = new LinkedList<Integer>();
lists.add(5);
lists.add(6);
2
3
首先调用无参构造函数,之后添加元素5,之后再添加元素6。具体的示意图如下:
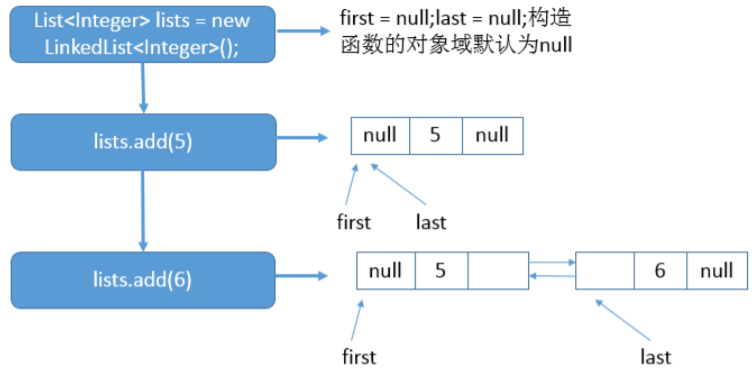
上图的表明了在执行每一条语句后,链表对应的状态。
# addAll()方法
addAll有两个重载函数,addAll(Collection)型和addAll(int, Collection) 型,我们平时习惯调用的addAll(Collection)型会转化为addAll(int, Collection)型。
public boolean addAll(Collection<? extends E> c) {
//继续往下看
return addAll(size, c);
}
2
3
4
addAll(size,c):这个方法,能包含三种情况下的添加,我们这里分析的只是构造方法,空链表的情况,看的时候只需要按照不同的情况分析下去就行了。
//真正核心的地方就是这里了,记得我们传过来的是size,c
public boolean addAll(int index, Collection<? extends E> c) {
//检查index这个是否为合理。这个很简单,自己点进去看下就明白了。
checkPositionIndex(index);
//将集合c转换为Object数组 a
Object[] a = c.toArray();
//数组a的长度numNew,也就是由多少个元素
int numNew = a.length;
if (numNew == 0)
//集合c是个空的,直接返回false,什么也不做。
return false;
//集合c是非空的,定义两个节点(内部类),每个节点都有三个属性,item、next、prev。注意:不要管这两个什么含义,就是用来做临时存储节点的。这个Node看下面一步的源码分析,Node就是linkedList的最核心的实现,可以直接先跳下一个去看Node的分析
Node<E> pred, succ;
//构造方法中传过来的就是index==size
if (index == size) {
//linkedList中三个属性:size、first、last。 size:链表中的元素个数。first:头节点 last:尾节点,就两种情况能进来这里
//情况一、:构造方法创建的一个空的链表,那么size=0,last、和first都为null。linkedList中是空的。什么节点都没有。succ=null、pred=last=null
//情况二、:链表中有节点,size就不是为0,first和last都分别指向第一个节点,和最后一个节点,在最后一个节点之后追加元素,就得记录一下最后一个节点是什么,所以把last保存到pred临时节点中。
succ = null;
pred = last;
} else {
//情况三、index!=size,说明不是前面两种情况,而是在链表中间插入元素,那么就得知道index上的节点是谁,保存到succ临时节点中,然后将succ的前一个节点保存到pred中,这样保存了这两个节点,就能够准确的插入节点了
//举个简单的例子,有2个位置,1、2、如果想插数据到第二个位置,双向链表中,就需要知道第一个位置是谁,原位置也就是第二个位置上是谁,然后才能将自己插到第二个位置上。如果这里还不明白,先看一下文章开头对于各种链表的删除,add操作是怎么实现的。
succ = node(index);
pred = succ.prev;
}
//前面的准备工作做完了,将遍历数组a中的元素,封装为一个个节点。
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//pred就是之前所构建好的,可能为null、也可能不为null,为null的话就是属于情况一、不为null则可能是情况二、或者情况三
Node<E> newNode = new Node<>(pred, e, null);
//如果pred==null,说明是情况一,构造方法,是刚创建的一个空链表,此时的newNode就当作第一个节点,所以把newNode给first头节点
if (pred == null)
first = newNode;
else
//如果pred!=null,说明可能是情况2或者情况3,如果是情况2,pred就是last,那么在最后一个节点之后追加到newNode,如果是情况3,在中间插入,pred为原index节点之前的一个节点,将它的next指向插入的节点,也是对的
pred.next = newNode;
//然后将pred换成newNode,注意,这个不在else之中,请看清楚了。
pred = newNode;
}
if (succ == null) {
/*如果succ==null,说明是情况一或者情况二,
情况一、构造方法,也就是刚创建的一个空链表,pred已经是newNode了,last=newNode,所以linkedList的first、last都指向第一个节点。
情况二、在最后节后之后追加节点,那么原先的last就应该指向现在的最后一个节点
了,就是newNode。*/
last = pred;
} else {
//如果succ!=null,说明可能是情况三、在中间插入节点,举例说明这几个参数的意义,有1、2两个节点,现在想在第二个位置插入节点newNode,根据前面的代码,pred=newNode,succ=2,并且1.next=newNode,已经构建好了,pred.next=succ,相当于在newNode.next =2; succ.prev = pred,相当于 2.prev = newNode, 这样一来,这种指向关系就完成了。first和last不用变,因为头节点和尾节点没变
pred.next = succ;
succ.prev = pred;
}
//增加了几个元素,就把 size = size +numNew 就可以了
size += numNew;
modCount++;
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
说明:参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。
在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下:
Node<E> node(int index) {
// assert isElementIndex(index);
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) {// 插入位置在前半段
Node<E> x = first;
for (int i = 0; i < index; i++)// 从头结点开始正向遍历
x = x.next;
return x;// 返回该结点
} else {// 插入位置在后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--)// 从尾结点开始反向遍历
x = x.prev;
return x;// 返回该结点
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
说明:在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
举例说明调用addAll函数后的链表状态:
List<Integer> lists = new LinkedList<Integer>();
lists.add(5);
lists.addAll(0, Arrays.asList(2, 3, 4, 5));
2
3
上述代码内部的链表结构如下:
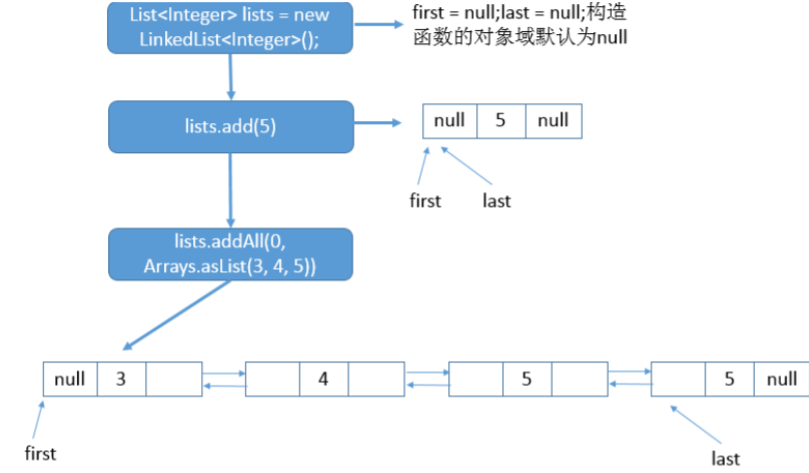
addAll()中的一个问题:
在addAll函数中,传入一个集合参数和插入位置,然后将集合转化为数组,然后再遍历数组,挨个添加数组的元素,但是问题来了,为什么要先转化为数组再进行遍历,而不是直接遍历集合呢?
从效果上两者是完全等价的,都可以达到遍历的效果。关于为什么要转化为数组的问题,我的思考如 下:
- 如果直接遍历集合的话,那么在遍历过程中需要插入元素,在堆上分配内存空间,修改指针域,这个过程中就会一直占用着这个集合,考虑正确同步的话,其他线程只能一直等待。
- 如果转化为数组,只需要遍历集合,而遍历集合过程中不需要额外的操作,所以占用的时间相对是较短的,这样就利于其他线程尽快的使用这个集合。说白了,就是有利于提高多线程访问该集合的效率,尽可能短时间的阻塞。
# remove(Object o)
/**
* Removes the first occurrence of the specified element from this list,
* if it is present. If this list does not contain the element, it is
* unchanged. More formally, removes the element with the lowest index
* {@code i} such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>
* (if such an element exists). Returns {@code true} if this list
* contained the specified element (or equivalently, if this list
* changed as a result of the call).
*
* @param o element to be removed from this list, if present
* @return {@code true} if this list contained the specified element
*/
///首先通过看上面的注释,我们可以知道,如果我们要移除的值在链表中存在多个一样的值,那么我们会移除index最小的那个,也就是最先找到的那个值,如果不存在这个值,那么什么也不做。
public boolean remove(Object o) {
//这里可以看到,linkedList也能存储null
if (o == null) {
//循环遍历链表,直到找到null值,然后使用unlink移除该值。下面的这个else中也一样
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
【unlink(xxxx)】
// Unlinks non-null node x.
//不能传一个null值过,注意,看之前要注意之前的next、prev这些都是谁。
E unlink(Node<E> x) {
// assert x != null;
//拿到节点x的三个属性
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//这里开始往下就进行移除该元素之后的操作,也就是把指向哪个节点搞定。
if (prev == null) {
//说明移除的节点是头节点,则first头节点应该指向下一个节点
first = next;
} else {
//不是头节点,prev.next=next:有1、2、3,将1.next指向3
prev.next = next;
//然后解除x节点的前指向。
x.prev = null;
}
if (next == null) {
//说明移除的节点是尾节点
last = prev;
} else {
//不是尾节点,有1、2、3,将3.prev指向1. 然后将2.next=解除指向。
next.prev = prev;
x.next = null;
}
//x的前后指向都为null了,也把item为null,让gc回收它
x.item = null;
size--;//移除一个节点,size自减
modCount++;
return element;//由于一开始已经保存了x的值到element,所以返回。
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# get(index)
【get(index)查询元素的方法】
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
//这里没有什么,重点还是在node(index)中
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
2
3
4
5
6
7
8
9
10
11
12
【node(index)】
/**
* Returns the (non-null) Node at the specified element index.
*/
//这里查询使用的是先从中间分一半查找
Node<E> node(int index) {
// assert isElementIndex(index);
//"<<":*2的几次方 “>>”:/2的几次方,例如:size<<1:size*2的1次方,
//这个if中就是查询前半部分
if (index < (size >> 1)) {//index<size/2
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//前半部分没找到,所以找后半部分
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# indexOf(Object o)
//这个很简单,就是通过实体元素来查找到该元素在链表中的位置。跟remove中的代码类似,只是返回类型不一样。
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 7、LinkedList的迭代器
在LinkedList中除了有一个Node的内部类外,应该还能看到另外两个内部类,那就是ListItr,还有一个是DescendingIterator。
【ListItr内部类】
private class ListItr implements ListIterator<E> {
}
2
看一下他的继承结构,发现只继承了一个ListIterator,到ListIterator中一看:
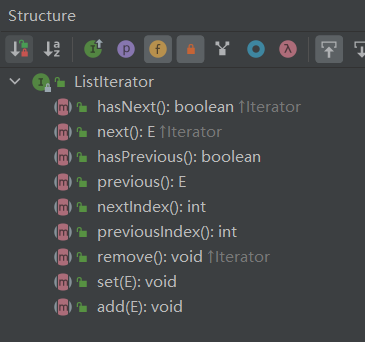
看到方法名之后,就发现不止有向后迭代的方法,还有向前迭代的方法,所以我们就知道了这个ListItr 这个内部类干嘛用的了,就是能让linkedList不光能像后迭代,也能向前迭代。
看一下ListItr中的方法,可以发现,在迭代的过程中,还能移除、修改、添加值得操作。
【DescendingIterator内部类】
private class DescendingIterator implements Iterator<E> {
//看一下这个类,还是调用的ListItr,作用是封装一下Itr中几个方法,让使用者以正常的思维去写代码,例如,在从后往前遍历的时候,也是跟从前往后遍历一样,使用next等操作,而不用使用特殊的previous。
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 总结
- linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构
- 能存储null值
- 跟arrayList相比较,就真正的知道了,LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好
- . 从源码中看,它不存在容量不足的情况
- . linkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值。
- linkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口。
代码在 LinkedList源码分析中3、类的属性